Graph Neural Network로 내 소비 패턴 예측하기
들어가며
일상에서 발생하는 수많은 거래들 - 카페에서 커피를 마시고, 식당에서 식사하고, 교통비를 결제하는 모든 순간들이 사실은 하나의 거대한 네트워크를 형성합니다. 이 글에서는 Graph Neural Network(GNN)이해를 위한 목적으로 GNN 활용하여 이러한 거래 데이터의 숨겨진 패턴을 발견하고, 새로운 거래의 금액을 예측하는 방법을 소개합니다.
GNN이란 무엇인가?
GNN(Graph Neural Network)은 “그래프 형태의 데이터”가 있는 거의 모든 문제를 풀 수 있습니다. 아래에 실생활·산업·연구에서 실제로 많이 쓰이는 대표적인 문제들을 정리했어요.
| 카테고리 | 구체적인 문제 예시 | 어떤 그래프인가? | 대표 논문 / 시스템 (2025년 기준) |
|---|---|---|---|
| 노드 분류 (Node Classification) | - 논문 주제 분류 (Cora, PubMed) - 유저의 관심사 예측 (Pinterest) - 단백질 기능 예측 | 논문 인용 그래프 유저-아이템 그래프 단백질 상호작용 네트워크 | GCN, GraphSAGE, GAT |
| 링크 예측 (Link Prediction) | - 친구 추천 (Facebook, LinkedIn) - 약물-약물 상호작용 예측 - 지식 그래프 완성 (Wikidata) | 소셜 네트워크 생물 네트워크 지식 그래프 | VGAE, SEAL, UltraGCN |
| 그래프 분류 (Graph Classification) | - 분자(화합물)의 독성/약리 예측 - 소셜 네트워크에서 악성 커뮤니티 탐지 - 프로그램 코드 취약점 탐지 | 분자 그래프 소셜 서브그래프 AST 그래프 | GIN, DiffPool, Graphormer |
| 추천 시스템 | - Netflix, YouTube, TikTok, Amazon 추천 - Pinterest 핀 추천 | 유저-아이템 이종 그래프 (Heterogeneous Graph) | PinSage, LightGCN, GraphRec |
| 교통 예측 | - 도시 교통 흐름 예측 - 고속도로 속도 예측 | 도로 네트워크 그래프 | Graph WaveNet, STGCN, DCRNN |
| 물리 시뮬레이션 / 로봇 | - 천 시뮬레이션, 유체 시뮬레이션 - 다중 로봇 협업 경로 계획 | 메쉬 그래프, 파티클 그래프 | MeshGraphNets, Graph Network Simulator |
| 지식 그래프 / LLM | - 사실 검증 (Fact-Checking) - RAG(Retrieval-Augmented Generation) - 멀티홉 질문 답변 | 엔티티-관계 그래프 | GraphRAG, GRE, KG-BERT |
| 이상 탐지 (Anomaly Detection) | - 금융 사기 거래 탐지 - 산업 설비 고장 예측 | 거래 네트워크, 센서 네트워크 | DOMINANT, AnomalyDAE |
| 생물·의약 | - 신약 후보 물질 스크리닝 - 단백질 구조 예측 - 뇌 연결망 분석 | 분자 그래프, 뇌 연결 그래프 | SchNet, AlphaFold (부분), Geomol |
| 소셜 네트워크 분석 | - 가짜뉴스 전파 예측 - 인플루언서 탐지 | 트윗 리트윗 그래프 | RGCN, DeeperGCN |
| 코드 분석 / 소프트웨어 엔지니어링 | - 버그 탐지 - 코드 자동 완성 - 악성코드 탐지 | CFG, AST, PDG 그래프 | GREAT, CodeGraph, Devign |
한마디로 요약하면
“노드와 노드 사이에 관계(엣지)가 있는 데이터라면 → 거의 다 GNN으로 풀 수 있다!”
실제 산업에서 2024~2025년 기준 가장 많이 돈 버는 GNN 활용 분야 TOP 3
- 추천 시스템 (Amazon, Netflix, TikTok, Pinterest) → 매출에 직접 영향
- 신약 개발 / 분자 설계 (Google DeepMind, Exscientia, Recursion) → 수백억 달러 규모
- 사기 탐지 / 금융 (PayPal, Ant Group, JPMorgan) → 손실 방지
전통적인 머신러닝의 한계
일반적인 머신러닝 모델은 데이터를 표(테이블) 형태로만 바라봅니다. 예를 들어, 각 거래를 독립적인 행(row)으로 취급하죠. 하지만 실제 세상의 데이터는 서로 연결되어 있습니다:
- 연속된 시간대의 거래는 나의 하루 패턴을 반영합니다
- 같은 카테고리의 거래는 비슷한 금액대를 형성합니다
- 특정 장소에서의 거래는 다른 패턴을 보입니다
그래프로 세상을 바라보기
GNN은 이러한 관계성을 그래프로 표현합니다:
- 노드(Node): 각각의 거래
- 엣지(Edge): 거래 간의 연결 관계
- 특성(Feature): 시간, 장소, 카테고리 등의 정보
소셜 네트워크에서 사람들이 노드이고 친구 관계가 엣지인 것처럼, 우리의 거래 데이터도 네트워크로 표현할 수 있습니다.
실제 구현: 거래 데이터를 그래프로 변환하기
데이터 구조 이해하기
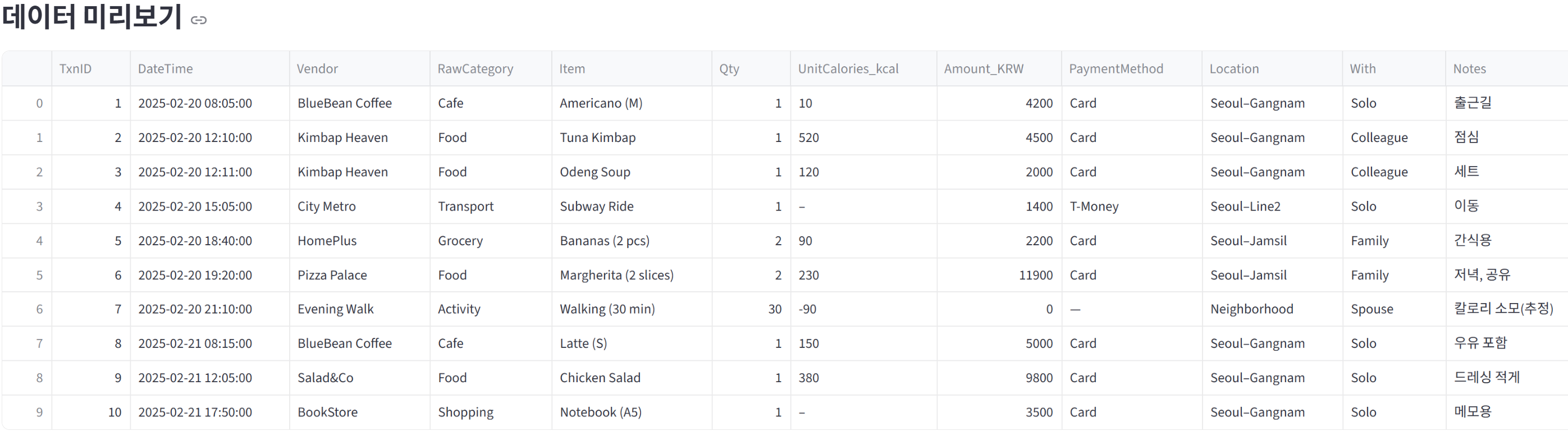
우리가 다루는 거래 데이터는 다음과 같은 정보를 담고 있습니다:
- DateTime: 거래 발생 시간
- Vendor: 상점 이름
- RawCategory: 카테고리 (Cafe, Food, Transport 등)
- Item: 구매한 상품
- Amount_KRW: 결제 금액
- PaymentMethod: 결제 수단
- Location: 장소
- With: 동행인
그래프 생성 전략
이 프로젝트에서는 두 가지 방식으로 거래들을 연결합니다:
1. 시간적 연결
연속된 거래를 양방향으로 연결합니다. 이는 하루의 소비 패턴을 학습하는 데 도움을 줍니다.
예시:
- 오전 8시 카페에서 커피 구매 ↔ 오전 8시 30분 편의점에서 간식 구매
- 이 두 거래는 서로 영향을 주고받으며 "아침 루틴"이라는 패턴을 형성합니다
2. 카테고리 연결
같은 카테고리의 거래들을 연결합니다. 너무 많은 연결을 방지하기 위해 각 거래당 최대 3개의 다른 거래와만 연결합니다.
예시:
- Cafe 카테고리의 모든 거래들이 서로 연결되어 "카페 소비 패턴"을 학습합니다
- 평균적으로 카페에서 얼마를 쓰는지, 어떤 시간대에 방문하는지 등의 정보를 공유합니다
노드 특성 설계
각 거래(노드)는 11개의 특성을 가집니다:
- 시간 정보: 시간(Hour), 요일(DayOfWeek), 날짜(Day)
- 거래 정보: 수량(Qty), 칼로리(UnitCalories_kcal)
- 범주형 정보: 상점, 카테고리, 상품, 결제수단, 장소, 동행인 (인코딩 후)
이 특성들은 StandardScaler로 정규화되어 모델이 학습하기 쉬운 형태로 변환됩니다.
GNN 모델 아키텍처 이해하기
GCN (Graph Convolutional Network)
이 프로젝트는 GCN을 사용합니다. GCN의 핵심 아이디어는 "이웃의 정보를 집계한다"입니다.
작동 원리:
- 각 노드가 자신의 특성을 가지고 있습니다
- 각 노드는 연결된 이웃 노드들의 정보를 수집합니다
- 자신의 정보와 이웃의 정보를 결합하여 새로운 표현을 만듭니다
- 이 과정을 여러 층(layer)에 걸쳐 반복합니다
실제 의미:
- 1층을 거치면: 바로 이웃 거래의 정보를 학습
- 2층을 거치면: 이웃의 이웃까지, 즉 2단계 떨어진 거래 정보를 학습
- 3층을 거치면: 더 넓은 범위의 패턴을 파악
모델 구조 상세
우리의 GNNExpensePredictor 모델은 다음과 같이 구성됩니다:
GNN 부분:
- GCN Layer 1: 입력 특성(11개) → 64차원으로 확장
- GCN Layer 2: 64차원 → 64차원 (패턴 정제)
- GCN Layer 3: 64차원 → 32차원 (압축)
MLP 부분:
- Fully Connected Layer 1: 32차원 → 32차원
- Fully Connected Layer 2: 32차원 → 1차원 (최종 금액 예측)
정규화 기법:
- Dropout (0.3): 과적합 방지
- ReLU 활성화 함수: 비선형성 추가
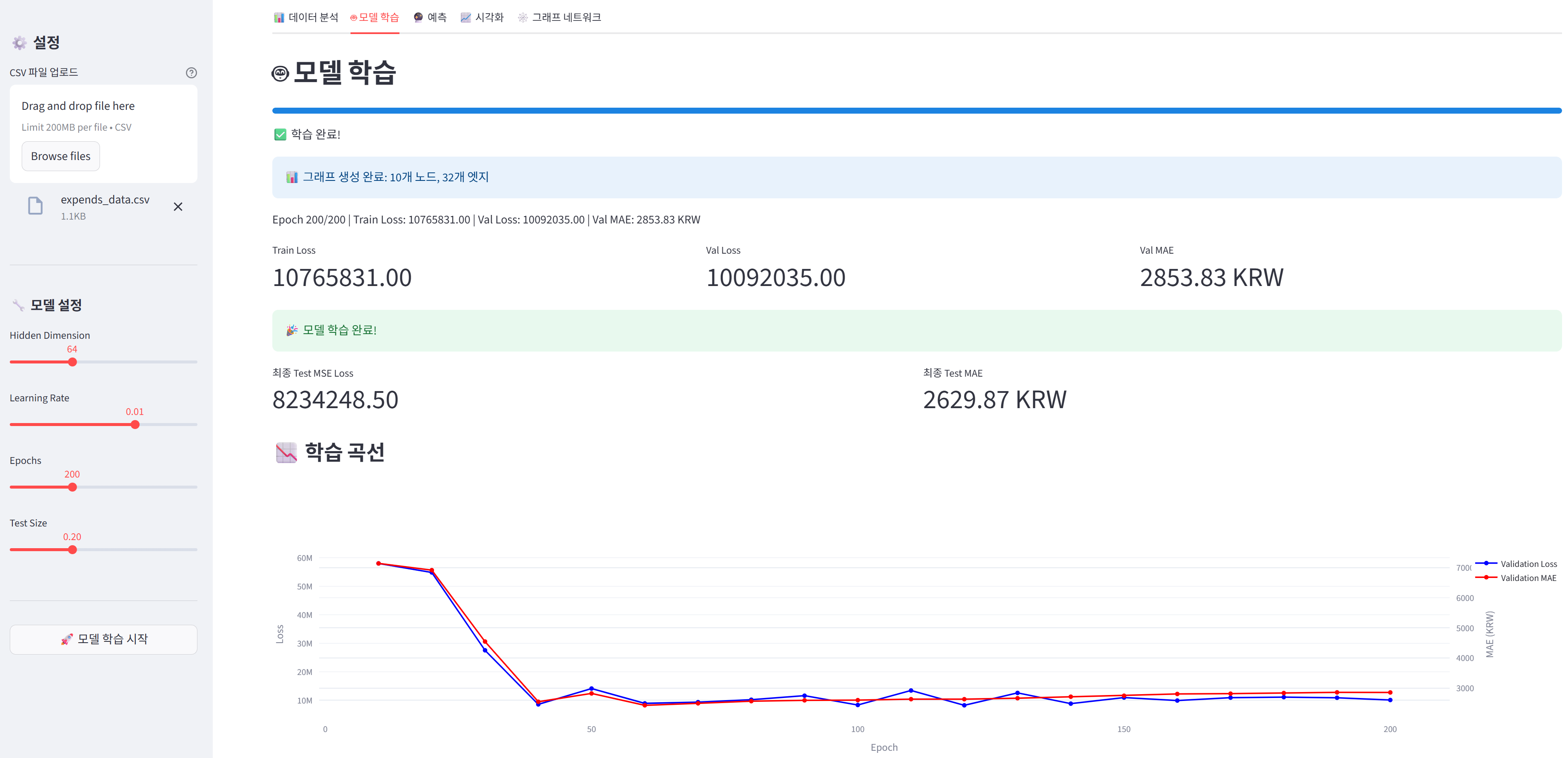
학습 과정의 이해
손실 함수: MSE (Mean Squared Error)
금액 예측이므로 회귀 문제입니다. MSE는 예측값과 실제값의 차이를 제곱하여 평균을 냅니다.
MSE = (1/n) × Σ(예측값 - 실제값)²
왜 MSE를 사용할까?
- 큰 오차에 더 큰 페널티를 부여합니다
- 금액 예측에서는 "2,000원 틀리는 것"보다 "10,000원 틀리는 것"이 훨씬 더 문제입니다
- 미분 가능하여 경사하강법에 적합합니다
평가 지표: MAE (Mean Absolute Error)
MAE는 예측 오차의 절대값 평균입니다.
MAE = (1/n) × Σ|예측값 - 실제값|
MAE의 장점:
- 직관적입니다: "평균적으로 ±1,234원 틀린다"
- 실제 금액 단위로 해석 가능합니다
학습 전략
Train/Test 분할:
- 80%를 학습용, 20%를 테스트용으로 분리
- 실제 세계에서 모델이 얼마나 잘 작동할지 검증
최적화:
- Adam 옵티마이저: 학습률을 자동으로 조정
- Learning Rate: 0.01 (적절한 학습 속도)
- Weight Decay: 5e-4 (L2 정규화, 과적합 방지)
Early Stopping 개념:
- 최고 성능의 모델을 'best_gnn_model.pt'로 저장
- Validation Loss가 가장 낮을 때의 모델을 보존
실전: 새로운 거래 예측하기
예측 과정 단계별 분석
입력 예시:
DateTime: 2025-02-22 12:30
Vendor: BlueBean Coffee
RawCategory: Cafe
Item: Americano (M)
Qty: 1
UnitCalories_kcal: 10
PaymentMethod: Card
Location: Seoul–Gangnam
With: Solo
처리 과정:
시간 특성 추출
- Hour: 12
- DayOfWeek: 5 (토요일)
- Day: 22
범주형 인코딩
- 학습 시 저장된 LabelEncoder를 사용
- 'BlueBean Coffee' → 숫자 인덱스로 변환
- 모든 범주형 변수를 동일하게 처리
정규화
- 학습 시 사용한 StandardScaler로 동일하게 변환
- 모델이 학습한 분포와 일치하도록 조정
그래프 생성
- 단일 노드로 간단한 그래프 생성
- Self-loop 엣지 추가 (자기 자신과의 연결)
예측 실행
- 모델 forward pass
- 최종 출력: 예상 금액 (예: 4,250원)
예측 정확도 검증
유사 거래 비교:
시스템은 과거 데이터에서 동일한 Vendor와 Item을 가진 거래를 찾아 평균을 계산합니다.
예시:
- 예측 금액: 4,250원
- 실제 평균: 4,200원
- 오차: 50원 (약 1.2%)
이를 통해 모델이 현실적인 예측을 하는지 확인할 수 있습니다.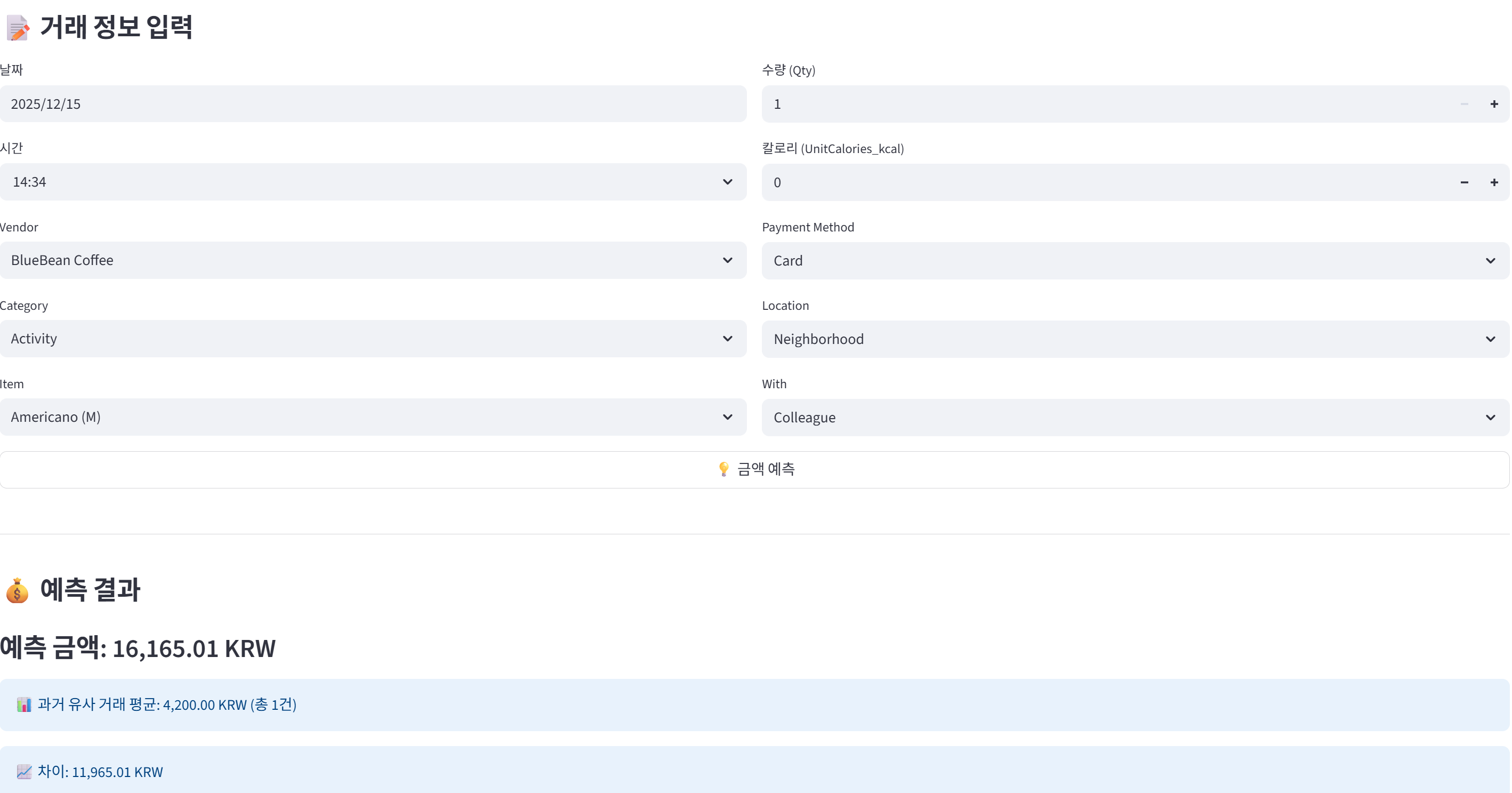
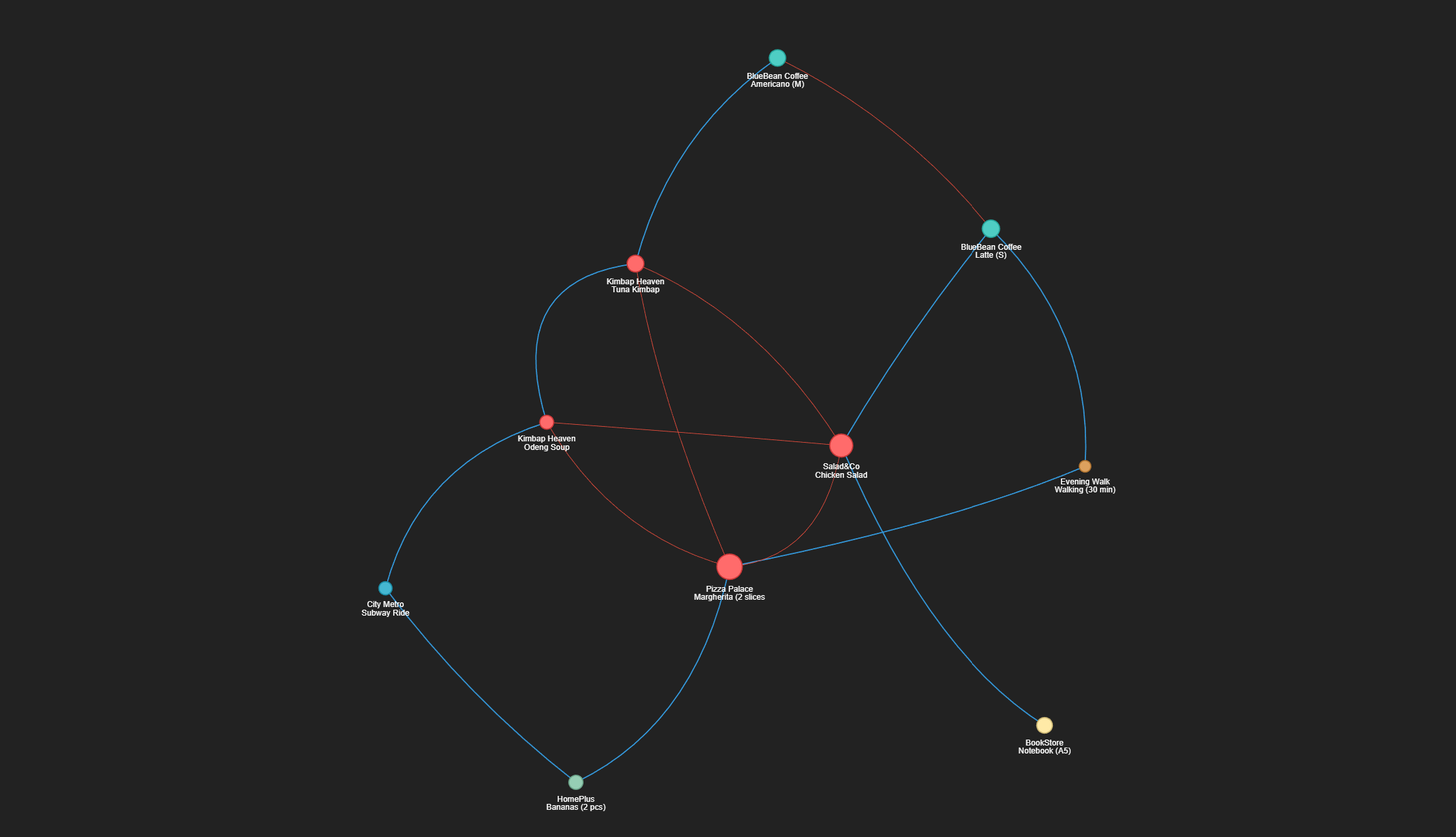
그래프 시각화로 인사이트 발견하기
거래 네트워크 시각화
PyVis를 사용하여 인터랙티브한 네트워크 그래프를 생성합니다.
시각적 요소의 의미:
노드 색상: 카테고리별로 구분
- 빨강: Food
- 청록: Cafe
- 파랑: Transport
- 녹색: Grocery
노드 크기: 거래 금액에 비례
- 큰 노드 = 고액 거래
- 작은 노드 = 소액 거래
엣지 색상:
- 파란색: 시간적 연결 (연속된 거래)
- 빨간색: 카테고리 연결 (같은 유형)
- 회색: 기타 연결
발견할 수 있는 패턴:
- 클러스터링: 같은 카테고리 거래들이 모여있는 형태
- 시간 흐름: 파란 엣지를 따라가면 하루의 소비 순서를 볼 수 있음
- 허브 노드: 많은 연결을 가진 노드는 대표적인 소비 패턴
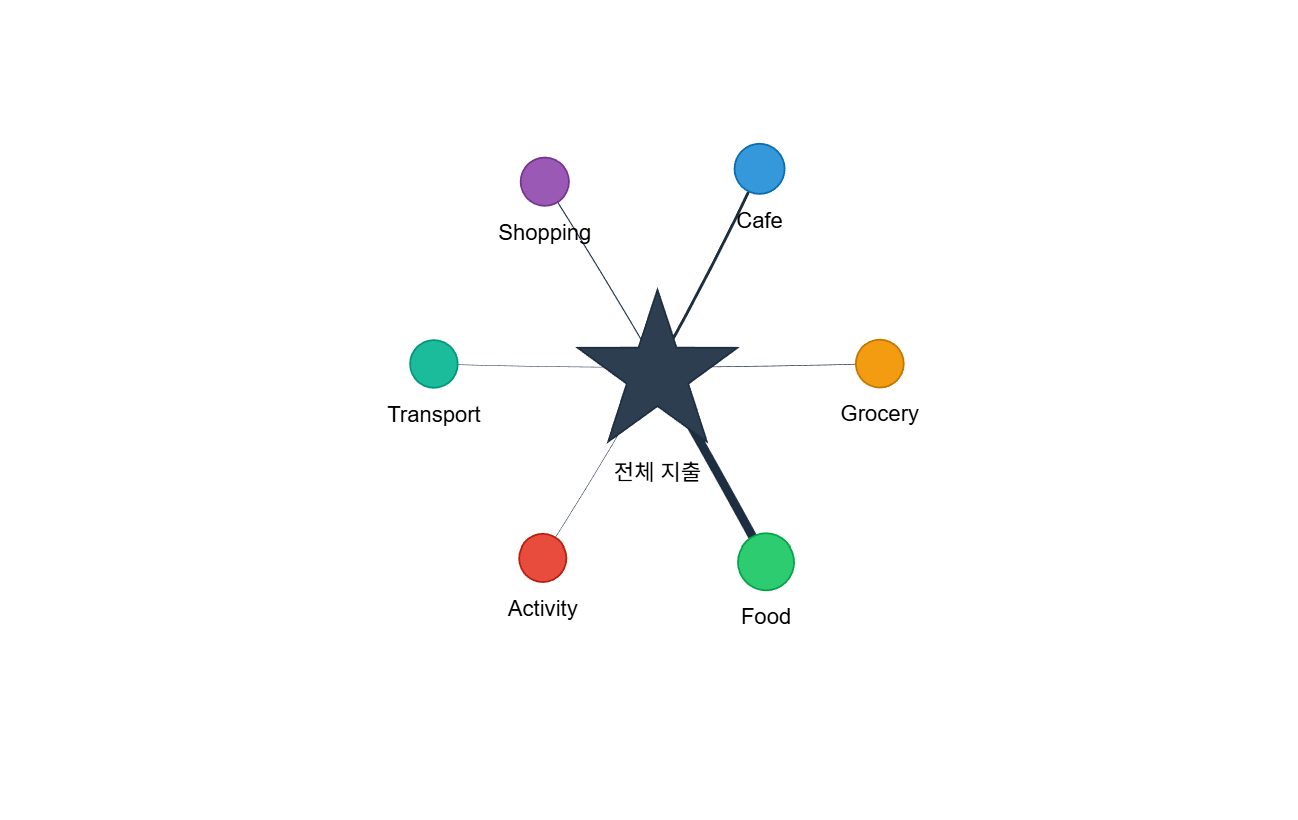
카테고리 네트워크
중앙에 "전체 지출"을 배치하고, 각 카테고리를 주변에 배치합니다.
인사이트:
- 노드 크기로 어떤 카테고리에 가장 많이 쓰는지 한눈에 파악
- 엣지 두께로 상대적 비중 비교
- 지출 구조의 균형 확인
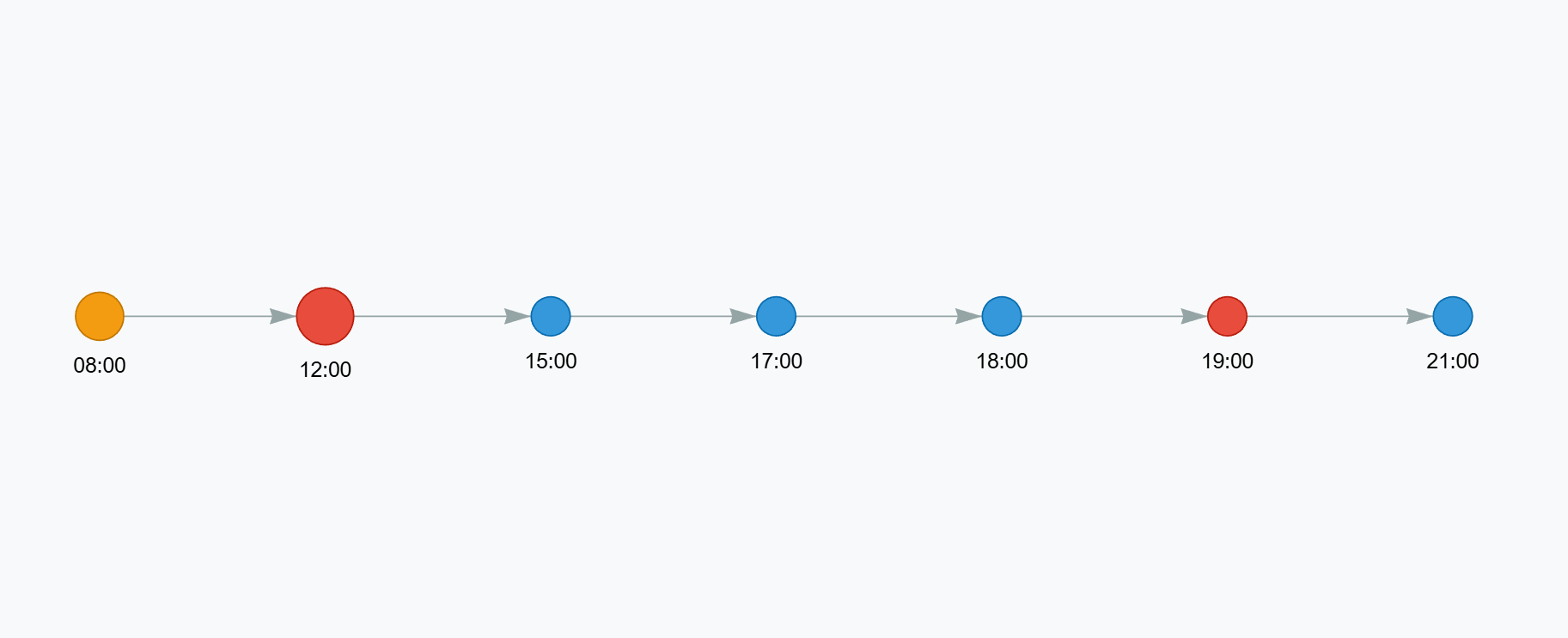
시간 흐름 그래프
시간대별 거래를 순서대로 배치하여 방향성 그래프를 생성합니다.
분석 가능한 항목:
어느 시간대에 거래가 집중되는가?
고액 지출은 주로 언제 발생하는가?
요일별 패턴의 차이는 무엇인가?
GNN의 장점: 왜 전통적인 방법보다 나은가?
1. 관계성 학습
기존 방법 (예: Random Forest, Linear Regression):
각 거래를 독립적으로 취급합니다.
예측 과정:
- "강남에서 12시 30분에 BlueBean Coffee에서 아메리카노를 산다"
- → 과거 비슷한 단일 거래들의 평균
GNN 방법:
거래 간의 관계를 함께 고려합니다.
예측 과정:
- "아침 8시에 빵집에서 빵을 샀고"
- "오전 10시에 편의점에서 간식을 샀으며"
- "이제 점심 시간에 강남의 카페에 왔다"
- → 이 패턴 전체를 바탕으로 예측
2. 정보 전파
GNN은 여러 층을 거치면서 멀리 떨어진 노드의 정보까지 활용합니다.
3-hop 정보 전달 예시:
1층 후:
- "바로 이전/이후 거래 정보 학습"
- "같은 카테고리의 인접 거래 학습"
2층 후:
- "2단계 떨어진 거래들의 패턴 파악"
- "아침-점심 연결 패턴 학습"
3층 후:
- "하루 전체의 소비 흐름 이해"
- "주간/주말 패턴 차이 인식"
3. 유연한 확장성
새로운 관계 추가가 쉽습니다:
- 같은 장소에서의 거래 연결
- 비슷한 시간대 연결
- 동행인이 같은 거래 연결
- 금액대가 유사한 거래 연결
각 관계 유형은 새로운 엣지로 표현되며, 모델은 자동으로 어떤 관계가 중요한지 학습합니다.
실용적 활용 사례
1. 개인 재정 관리
예산 예측:
- "다음 주 카페 지출이 얼마나 될까?"
- 과거 패턴을 바탕으로 주간 예산 추정
이상 거래 탐지:
- 예측값과 실제값의 차이가 크면 경고
- "평소 5,000원인데 오늘 15,000원?"
2. 소비 패턴 분석
시각화를 통한 발견:
- 주말에 외식비가 급증하는 패턴
- 특정 요일에 특정 카페를 자주 가는 습관
- 동행인에 따른 지출 금액 변화
개선 방향 도출:
- 불필요한 반복 지출 식별
- 대안 찾기 (더 저렴한 옵션)
3. 추천 시스템
상황 기반 추천:
- "지금 시간, 이 장소에서 보통 이런 걸 사셨어요"
- 과거 그래프 패턴을 활용한 개인화
금액 가이드:
"이 상점에서 평균 8,000원 정도 지출하세요"
예산 초과 방지
모델 성능 개선 전략
하이퍼파라미터 튜닝
Hidden Dimension:
- 기본값: 64
- 더 큰 값 (128, 256): 복잡한 패턴 학습, 하지만 과적합 위험
- 더 작은 값 (32): 빠른 학습, 단순한 패턴만 포착
Learning Rate:
- 높은 값 (0.1): 빠른 수렴, 하지만 불안정
- 낮은 값 (0.001): 안정적, 하지만 느림
- 적응형 조정: ReduceLROnPlateau 사용 권장
Epochs:
너무 적으면: 덜 학습됨
너무 많으면: 과적합
Early Stopping으로 최적 시점 자동 탐지
특성 공학
추가 가능한 특성:
- 월말/월초 여부 (급여일 전후 패턴)
- 공휴일 여부
- 날씨 정보 (비올 때 배달 증가)
- 이전 거래와의 시간 간격
파생 특성:
- 최근 7일 평균 지출
- 같은 요일 같은 시간대 평균
- 카테고리별 누적 지출
앙상블 기법
GNN + 전통적 모델 결합:
- GNN으로 관계성 기반 예측
- XGBoost로 개별 특성 기반 예측
- 두 예측의 가중 평균
다중 GNN 모델:
- 서로 다른 그래프 구조 사용
- 서로 다른 하이퍼파라미터
- 예측 평균 또는 Voting
한계와 고려사항
1. 데이터 의존성
필요한 데이터 양:
- 최소 수백 개의 거래 필요
- 각 카테고리별로 충분한 샘플
- 시간적 다양성 (여러 요일, 시간대)
데이터 품질:
- 정확한 카테고리 라벨링 필수
- 이상치 처리 (오타, 잘못된 금액)
- 일관된 형식
2. 새로운 값 처리
미등록 Vendor나 Item:
- LabelEncoder가 학습하지 못한 값
- 해결책: Unknown 카테고리 추가 또는 One-Hot Encoding
계절성:
- 여름과 겨울의 소비 패턴이 다름
- 정기적인 재학습 필요
3. 계산 복잡도
그래프 크기 증가:
- 노드 수가 많아지면 메모리 사용량 증가
- 엣지 수가 많아지면 학습 시간 증가
최적화 방법:
- 샘플링: 일부 노드만 사용하여 학습
- Mini-batch: 전체 그래프를 한 번에 처리하지 않음
- GraphSAINT 등의 고급 샘플링 기법
확장 가능성
1. 다중 작업 학습
금액 예측 외에 추가 작업:
- 카테고리 분류 (자동 태깅)
- 결제 수단 예측
- 이상 거래 탐지 (Binary Classification)
하나의 GNN 모델로 여러 예측을 동시에 수행하면 효율적입니다.
2. 시계열 GNN
현재는 정적 그래프이지만, 시간에 따라 변화하는 동적 그래프로 확장 가능:
- Temporal Graph Network (TGN)
- 시간에 따른 엣지 가중치 변화
- 패턴의 진화 추적
3. 이종 그래프 (Heterogeneous Graph)
여러 타입의 노드와 엣지:
- 노드 타입: 거래, 상점, 카테고리, 사용자
- 엣지 타입: 구매, 소속, 유사, 동행
GraphSAGE, HGT 등의 고급 모델 활용
4. 설명 가능한 AI
예측 근거 제시:
- GNNExplainer: 어떤 이웃 노드가 예측에 영향을 주었는가?
- Attention Mechanism: 중요한 관계에 더 많은 가중치
사용자 신뢰 구축:
- "이 금액을 예측한 이유는 지난주 같은 시간대에 비슷한 금액을 사용했기 때문입니다"
실무 적용 시 체크리스트
데이터 준비
- 최소 500개 이상의 거래 데이터 확보
- 날짜/시간 형식 통일
- 범주형 변수 정리 (오타 수정)
- 금액 단위 확인 (원/달러 등)
모델 개발
- Train/Validation/Test 분할 (60/20/20 또는 70/15/15)
- Baseline 모델 구축 (평균값, 선형회귀)
- GNN 모델 학습
- 성능 비교 (MAE, RMSE)
평가 및 검증
- 교차 검증 (K-Fold)
- 시간적 분할 (과거로 학습, 미래로 테스트)
- 카테고리별 성능 분석
- 이상치 처리 전후 비교
배포 및 운영
- 모델 저장 형식 결정 (.pt, ONNX)
- API 서버 구축 (FastAPI, Flask)
- 모니터링 대시보드 (Streamlit, Grafana)
- 정기 재학습 스케줄 설정
결론: GNN이 여는 새로운 가능성
Graph Neural Network는 단순히 데이터를 표로 보는 것을 넘어, 관계의 네트워크로 이해하게 합니다. 거래 데이터에 GNN을 적용함으로써:
얻을 수 있는 것:
- 더 정확한 금액 예측
- 소비 패턴의 시각적 이해
- 관계 기반 인사이트 발견
배울 수 있는 것:
- 그래프 사고방식 (Graph Thinking)
- 딥러닝의 실용적 적용
- 데이터 시각화의 힘
확장할 수 있는 것:
- 다양한 도메인으로 응용 (SNS, 추천, 약물 발견)
- 더 복잡한 그래프 모델 탐구 (GAT, GraphSAINT)
- 실시간 예측 시스템 구축
이 프로젝트는 GNN의 시작점입니다. 여기서 배운 개념들은 소셜 네트워크 분석, 지식 그래프, 분자 구조 예측 등 수많은 분야에 적용될 수 있습니다.
여러분의 데이터에는 어떤 그래프가 숨어있을까요? 이제 그 관계의 네트워크를 발견하고, GNN으로 학습할 차례입니다.
다음 단계:
- 직접 데이터를 수집하고 그래프로 변환해보기
- 다양한 엣지 생성 전략 실험하기
- 시각화를 통해 새로운 패턴 발견하기
- 실제 서비스에 배포해보기
참고 자료:
- PyTorch Geometric 공식 문서
- GNN 논문: "Semi-Supervised Classification with Graph Convolutional Networks" (Kipf & Welling, 2017)
- Graph Representation Learning Book (William L. Hamilton)
(프로젝트 코드: 이 문서에서 설명한 내용 및 프로젝트 코드에 대한 문의는 언제든 환영합니다)
