같은 데이터, 다른 결과: RDB와 온톨로지(Knowledge Graph)의 결정적 차이
공장은 이미 데이터로 가득 차 있다.
설비 이력, 공정 조건, 품질 불량, 작업자 기록까지.
MES, ERP, QMS를 통해 우리는 수년 치 데이터를 차곡차곡 쌓아왔다.
그런데 이상하다.
데이터는 넘치는데, 공장은 여전히 사람에게 묻는다.
“왜 이 불량이 난 거지?”
“다음에는 어떻게 해야 하지?”
데이터는 있는데, 이유는 없다
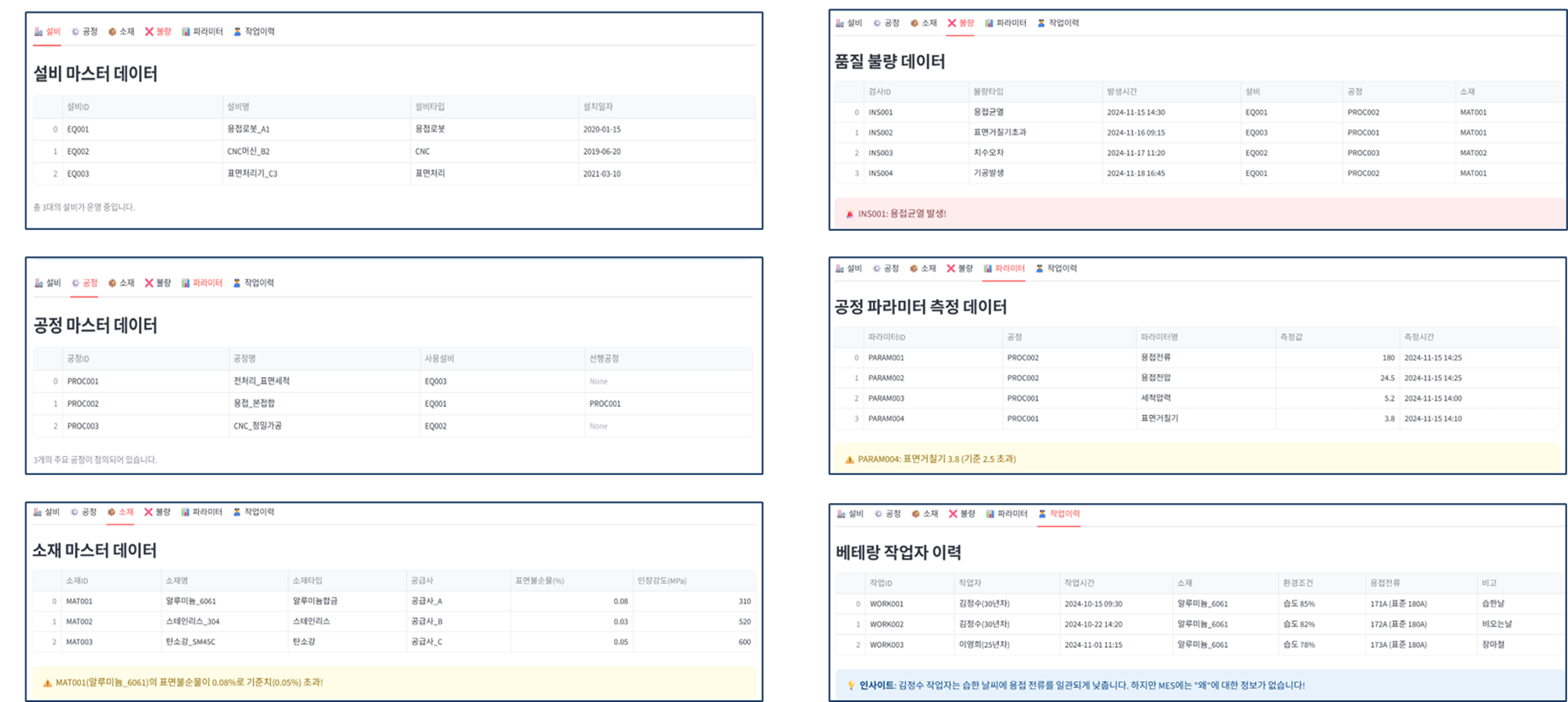
한 용접 공정에서 균열 불량이 발생했다고 해보자.
시스템에는 이렇게 기록되어 있다.
- 설비: EQ001
- 공정: 용접 본접합
- 소재: 알루미늄 6061
- 용접전류: 180A
- 습도: 85%
- 작업자: 30년차 베테랑
데이터는 완벽하다.
하지만 이 데이터만으로 시스템은 아무 말도 하지 않는다.
왜냐하면 이 모든 정보의 ‘관계와 의미’는 데이터베이스에 없기 때문이다.
RDB가 가진 한계 – 관계는 암묵적이다
관계형 데이터베이스(RDB)는 매우 훌륭한 기술이다.
정확하고 빠르며, 대량의 데이터를 안정적으로 저장한다.
하지만 RDB에서 관계란 대부분 이런 형태다.
- 같은 ID
- 외래키
- 조인 조건
즉, “연결은 있지만, 의미는 없다.”
알루미늄 6061이 왜 균열에 민감한지, 습도가 왜 위험을 키우는지,
전류가 기준을 넘으면 무엇이 달라지는지…
이 모든 것은 사람의 경험과 해석에만 존재한다.
그래서 우리는 항상 “사람에게 묻는다”
불량이 발생하면 결국 이렇게 된다.
- 회의실에 사람들이 모이고
- 베테랑이 말한다
“이날 습도가 높았잖아. 알루미늄이면 전류를 낮췄어야지.”
이 판단은 맞다.
하지만 문제는 이 지식이 다음 공정에는 전혀 남지 않는다는 것이다.
다음에 같은 조건이 와도, 시스템은 다시 묻고, 사람은 다시 설명한다.
지식 그래프는 무엇이 다른가
지식 그래프(Knowledge Graph)는
데이터를 저장하는 방식이 다르다기보다,
세상을 표현하는 방식이 다르다.
지식 그래프에서는 이렇게 표현한다.
- 알루미늄 6061 → 균열 민감도 높음
- 습도 상승 → 균열 위험 증가
- 전류 과다 → 균열 가능성 증가
- 이 조합 → 용접 균열 발생 가능
여기서 중요한 것은
관계 자체가 ‘의미를 가진 문장’이라는 점이다.
같은 데이터, 완전히 다른 질문
이제 시스템에 이렇게 물을 수 있다.
“왜 이 불량이 발생했는가?”
“이 조건에서 위험 요소는 무엇이었는가?”
“다음에는 무엇을 바꿔야 하는가?”
RDB는 데이터를 나열하지만, 지식 그래프는 이유를 설명한다.
베테랑의 판단이 자산이 되는 순간
지식 그래프의 진짜 가치는 여기에 있다.
베테랑이 경험으로 알고 있던 판단,
“알루미늄 + 고습 = 전류 낮춤”
이것을
- 규칙으로
- 관계로
- 지식으로 남길 수 있다.
그 순간,
그 지식은 더 이상 개인의 기억이 아니라
조직의 자산이 된다.
우리는 무엇을 만들고 싶은가
데이터를 더 많이 쌓는 공장인가,
아니면
판단하고 학습하는 공장인가.
RDB는 기록에 강하다.
하지만 이해와 추론은 지식 그래프의 영역이다.
마무리하며
RDB는 ‘무엇이 일어났는가’를 저장한다.
지식 그래프는 ‘왜 그렇게 되었는가’를 남긴다.
AI를 공장에 적용하고 싶다면, 모델보다 먼저 물어야 할 질문은 이것이다.
“우리 데이터는, 의미를 가지고 있는가?”


김정현 운영자 -
1개월, 2주
좋은 글 잘 읽었습니다. 이 글을 읽으면서 AI에 대해 다시 한번 생각해봤습니다.
최근 LLM을 활용하면서 마치 모니터 저 너머에 사람이 앉아있을 것 같다는 착각을 하곤합니다.
LLM도 사람이 하나하나 가르쳐 주진 않았지만, 데이터를 통해 그 의미를 스스로 연결시키는 작업을 했을 것입니다.
우리가 AI에게 기대하는 것은 공장에서 만들어진 무수한 데이터를 AI가 스스로 학습하고 관련성을 연결하는 것입니다. 그동안 좋은 결과가 없었던 것은 혹시 데이터가 부족했거나, AI에게 던저 준 데이터의 적절성 문제는 아닌지 의문이듭니다.